Introduction¶
What is EpiDemo?¶
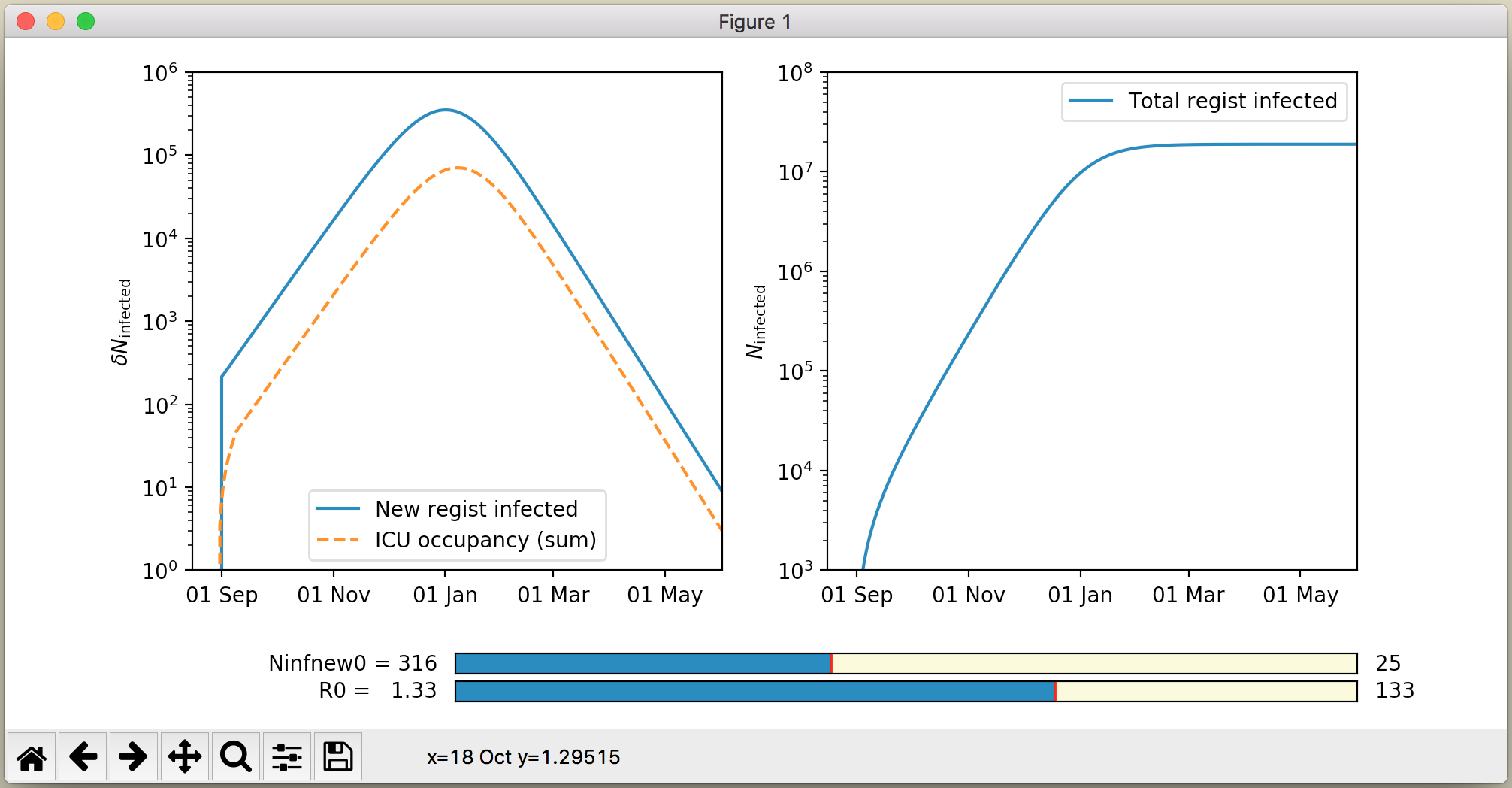
EpiDemo is a simple autoregressive model of “epidemic dynamics”. As the name says, it is meant as a demonstration model, not as a professional research tool. The goal is to help scientifically minded non-experts get a feeling for, and understanding of, the dynamics of an epidemic, with a particular emphasis on Covid-19. It requires a bit of Python programming on the side of the user, so it is not quite plug-and-play. But it contains a set of visualization graphical user interface (GUI) tools to make it easy to vary parameters and see how the model responds.
Motivation¶
The Covid-19 crisis has forced ordinary citizens to learn the basics of epidemiology in order to understand the nature of the crisis. We all heard about R_0 and the concept of exponential growth. These concepts are understandable to most people, at least qualitatively. But obtaining a more quantitative grasp on the matter is much harder. If R_0=1.3 and stays that way for the forseeable future, how much time would we have before the hospitals get overloaded? If we would do nothing to reduce R_0, how bad will it get? Small numbers today may give a false sense of security, while large numbers can sometimes look worse than they are. Our intuition has been trained under normal circumstances and in daily settings. This intuition is helpless when facing exponential growth curves and dealing with statistics involving 83 million people.
I am an astrophysicist, not an epidemiologist. At Heidelberg University, Germany, I teach astrophysics, computational physics, physics of everyday life, and several other courses. Those are my fields of expertise. Not epidemiology. I am therefore not and expert, by any standard. But astrophysicists are trained to work with vastly different scales, and use mathematics to try to understand whatever needs to be understood. I created EpiDemo largely as a “toy model” to get a better understanding of the dynamics of the Covid-19 crisis myself. In that, I am just one among thousands of like-minded people around the world that apply their skills to the Covid-19 crisis.
So why do I put EpiDemo online?
It is because I believe that, in addition to reading up on recent literature, a key element of learning about the current Covid-19 crisis is to do some calculations onself, for instance by “playing” with a toy model such as EpiDemo.
Of course, we cannot expect to become an expert in epidemiology in this way. In the end we must trust the professional scientists. But how, if not by educating ourselves, can we develop reasonably well-founded opinions on important issues such as Covid-19 containment measures?
Now that a vaccine seems to be imminent, why do I put it online now?
During the first wave, we did not yet know what we were facing. It was absolutely clear that a hard lockdown was the only right thing to do in the face of the uncertainty. Now that we know much more about the virus and the corresponding disease, finding the right balance between total lockdown and laissez faire is much more tricky. The vaccine will not be available to everyone overnight. So we could still be facing some hard time ahead.
So I hope that EpiDemo can help gaining a better intuition for the dynamics of epidemics in general and Covid-19 in particular. But please keep in mind that the model result are at most as good as the input parameters fed into the model.
Disclaimer¶
This software is NOT meant for professional use. It is strictly meant for demonstration/educational purposes. It should not be used for medical decision, policy decisions, or any other purposes for which errors in, or wrong usage of, this software could lead to damage of any kind. Any medical or policy decisions should be advised by professional individuals with the appropriate expertise.
This software is not an epidemic dynamic model in its own right. It is merely a program that integrates a set of coupled equations to simulate the dynamics of an epidemic in a heterogeneous population. Its default parameters are tuned to the Covid-19 crisis, but these values might be wrong. The user of this program is responsible for all the input parameters and initial conditions, and the outcome of the program will be entirely dependent on these input parameters.
Some of the calculational methods are known oversimplifications, such as the use of “top-hat” models for convolving some of the quantities in the time domain, for instance for the duration of a person’s infectuousness. For demonstration purposes (for which this software is written) this does not likely change the results much, but for accurate predictive models it may.
Model summary¶
Introductory literature¶
Good textbooks to epidemic modeling are e.g. “Modeling infectious diseases in humans and animals” by Keeling and Rohani (Princeton University Press), or “Epidemics - Models and Data using R” by Bjornstad (Springer).
Standard modeling approach in the literature¶
In epidemiology the standard model is the SIR or the SEIR model of Kermack and McKendrick (1927), and all its offsprings. These models express the dynamics as a set of coupled first order ordinary differential equations. The letters SIR stand for the “Susceptible”, “Infected” and “Recovered” portions of the population. The SEIR model adds a catagory “Exposed” to the model, which is a way to include the delay between becoming infected (exposed) and becoming infectuous (infected).
Our modeling approach: the “look back” method¶
We choose a different approach. In our model, the delay between being exposed and becoming infectuous is modeled explicitly using a “look back” method: If at time \(t\) (where \(t\) is in days) we wish to compute the rate of new infections, we look back one generation time \(t_g\) into the past to see how many people were infected back then. In addition, we convolve this with a time window function, since the generation time \(t_g\) is merely the mean time between two successive infections. This time window function expresses the typical time during which an infected person is infectuous. So in the simplest version of our model there is only one dynamic function: \(\delta N_{\mathrm{inf}}(t)\), which is the number of people being infected on day \(t\). The cumulative sum \(N_{\mathrm{inf}}(t)\) over all days up to \(t\) gives the total number of people who once had the virus up to that day. Assuming permanent immunity, the number of susceptibles (S) is then \(S(t) = N_{\mathrm{pop}} - N_{\mathrm{inf}}(t)\). The catagories E, I and R are then no longer required as dynamic variables (they can be computed from \(\delta N_{\mathrm{inf}}(t)\) and \(N_{\mathrm{inf}}(t)\)).
There are several advantages over this approach compared to the SEIR model:
It is more like a simulation than a set of abstract differential equations, and thus easier to understand for non-experts. This also makes it is easier to add additional effects to the model such as a pre-existing base immunity, waning immunity, stochasticity, etc.
It is a more accurate representation of the true dynamics in situations where a government decree can suddenly (from one day to the next) change the infectivity.
One can easily build in other delays using the “look back” method, such as the delay between onset of symptoms and the reporting of test results into national databases.
The \(\delta N_{\mathrm{inf}}(t)\) is closely akin to the kind of data that are provided in the databases such as the Johns Hopkins University database and the Robert Koch Institute database, even though there is of course a time lag and an incompleteness of these reports in comparison to the true \(\delta N_{\mathrm{inf}}(t)\).
Note also that our approach is not new. It is a form of “Auto-Regression-Moving-Average model” (ARMA model), which is commonly used in time series analysis. Although to my knowledge not very commonly used in epidemic dynamic modeling, one can find examples of its use in epidemic dynamics in the book “Epidemics - Models and Data using R” by Bjornstad.
The EpiDemo model also includes the possibility of multi-group modeling, in which the population is split into groups (e.g. age catagories, behavioral catagories, medical catagories, or even catagories such as medical staff versus patients or nurses versus elderly), with cross infections between the groups.
As a final note: the “look back” algorithm is really a very simple algorithm. In its simplest form (one group, with a one-day infectivity window), it is simply
which is successively evaluated for steps of increasing \(t\) by one. The actual model includes more realism, but the basic principle remains as simple as that.